This is code that will pull each job posting for a specific job title in a specific location (or Nationally) and return / plot the percentage of the postings that have certain keywords. The code is set up to search for all words except stopwords, and other user-defined words (there is probably a much more efficient way of doing this, but I had no need to change this once I had the code running). This allows the user to see common technical skills, as well as common soft skills that should be included on a resume.
NOTE: I got this idea from https://jessesw.com/Data-Science-Skills/. Obviously, just using his code would be of no real benefit to me, as I wanted to use the idea to help better my skills with scraping data from HTML files. So, I used his idea and developed my own code from scratch. I also modified the overall process a bit to better fit my needs.
NOTE2: This code will not be able to identify multiple-word skills. So, for example, ‘machine learning’ will show up as either ‘machine’ or ‘learning’. However, ‘machine’ could show up for other phrases than ‘machine learning’.
To run the code, change the city, state, and job title to whichever you wish. After generating the plot, you might need to add ‘keywords’ to the attitional_stop_words list if you do not want them to be included.
from bs4 import BeautifulSoup
import urllib
import re
from time import sleep
from collections import Counter
from nltk.corpus import stopwords
import pandas as pd
%matplotlib inline
import matplotlib.pylab as plt
from matplotlib.backends.backend_pdf import PdfPages
plt.rcParams['figure.figsize'] = (10.0, 8.0)
Define the city, state, and job title.
city = 'Seattle'
state = 'WA'
job_title = 'Data Scientist'
Define a function that will take the url and pull out the text of the main body as a list of strings. Remove common words such as ‘the’, ‘or’, ‘and’, etc.
def clean_the_html(url):
# First try to download the html file
try:
html = urllib.urlopen(url)
except:
return
#print url
# Open html in BeautifulSoup
soup = BeautifulSoup(html)
# Extract everything within the <p> tags
text = soup.findAll('body')
word_list = ''
for line in text:
word_list = ' '.join([word_list,line.get_text(' ',strip=True).lower()])
# Remove non text characters from list
word_list = re.sub('[^a-zA-Z+3]',' ', word_list)
list_of_words = word_list.encode('ascii','ignore').split()
stop_words = set(stopwords.words("english"))
additional_stop_words = ['webfont','limited','saved','disability',\
'desirable','nreum','skills','net','+','k',\
'above','it','end','excellent','join','want',\
'how','well','sets','like','page','home','demonstrated',\
'other','re','size','etc','gettime','work','ms',\
'zqdxyrmad','description','value','re','transactionname',\
'education','daylight','highly','bodyrendered',\
'amazon','new','bam','techniques','com',city.lower(),\
state.lower(),'min','need','email','job','content','features',\
'service','wa','id','modern','looking','eastern',\
'qualifications','teams','based','false','times',\
'software','career','ability','platform','years','data',\
'date','product','team','time','agent','information',\
'methods','candidate','customers','back','info','scientist',\
'experience','apply','us','engineering','learning',\
'strong','business','design','title','large','e','document',\
'science','company','location','field','communication',\
'customer','tools','used','research','model',\
'opportunity','online','including','degree',\
'preferred','across','beacon','using','friend','function',\
'position','window','role','3','written','build',\
'presentation','getelementbyid','technical','posted',\
'newrelic','decision','log','errorbeacon','solutions',\
'applicationtime','enable','responsibilities',\
'models','applicationid','complex','licensekey',\
'high','browser','d','nr','develop','please',\
'selection','queuetime','cookies','icimsaddonload',\
'computer','icims','scientists','great','returning',\
'systems','writing','united','working','iframe',\
'analyses','applications','try','related',\
'states','languages','yghvbe','language','one',\
'site','llc,','category','personalized','knowledge']
# Remove words from list
truncated_list = [w for w in list_of_words if not (w in stop_words or \
w in additional_stop_words)]
truncated_set = set(truncated_list)
truncated_list = list(truncated_set)
return truncated_list
Define a function to generate a list of urls for a given search (i.e., ‘Data Scientist’). Each search result page has 10 non-sponsored links. Search the first url for ‘Jobs # to # of ###’ in order to determine how many iterations to perform.
def gen_url_list(city,state,job_name):
base_url = 'http://www.indeed.com/'
job_term = re.sub(' ','+',job_name.lower())
search_url = ''.join([base_url,'jobs?q=',job_term,'&l=',city,'%2C+',state])
try:
html = urllib.urlopen(search_url)
except:
return
soup = BeautifulSoup(html)
total_jobs = soup.find(id = 'searchCount').string.encode('utf-8')
job_nums = int([int(s) for s in total_jobs.split() if s.isdigit()][-1]/10)
print total_jobs
job_URLS = []
for i in range(job_nums+1):
if i % 10 == 0:
print i
page_url = ''.join([base_url,job_term,'&1=',city,'%2C+',state,\
'&start=',str((i+1)*10)])
html = urllib.urlopen(search_url)
soup = BeautifulSoup(html)
job_link_area = soup.findAll('h2',{'class':'jobtitle'})
for link in job_link_area:
match_href = re.search('<a\shref="(.+?)"',str(link))
if match_href:
job_URLS.append([base_url + match_href.group(1)])
return job_URLS
Now that we have a list of all of the URLs of job postings, pull the information from each site, clean the data, and populate the keyword list.
def job_posting_analysis(url_list):
job_skills = []
count = 0
for url in url_list:
count += 1
if count % 10 == 1:
print count
posting_keywords = clean_the_html(url[0])
if posting_keywords:
job_skills.append(posting_keywords)
sleep(0.5)
return job_skills
Now that the various functions are defined, run the code.
First: run gen_url_list for the specified city, state, and jobtitle in order to generate
the list of job posting links
Second: run job_posting_analysis to pull out the job_skills listed for each job posting.
print 'Crawl indeed.com for ' + city + ', ' + state + ' ' + job_title + \
' postings and generate a list of all of the job posting links'
url_list = gen_url_list(city,state,job_title)
print "Given the job posting links, pull out the keywords for each posting"
job_skills = job_posting_analysis(url_list)
Now that we have the list of keywords in the job postings, calculate the number of postings in which each keyword appears. Then plot the data on a bar graph
skill_frequency = Counter() # This will create a full counter of our terms.
[skill_frequency.update(item) for item in job_skills] # List comp
print skill_frequency.items()
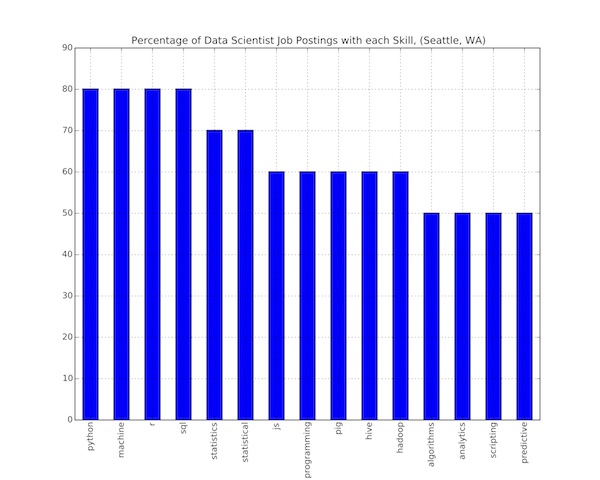
data_to_plot = pd.DataFrame(skill_frequency.items(),columns = ['Skill','Occurances'])
data_to_plot.Occurances = (data_to_plot.Occurances)*100/len(job_skills)
data_to_plot.sort(columns = 'Occurances',ascending = False,inplace = True)
test_data = data_to_plot.head(15) # plot only top 15 skills
print data_to_plot.head(20)
frame = test_data.plot(x='Skill',kind='bar',legend=None,\
title='Percentage of Data Scientist Job Postings with each Skill, ('\
+ city + ', ' + state + ')')
#plt.ylim([40,90])
fig = frame.get_figure()
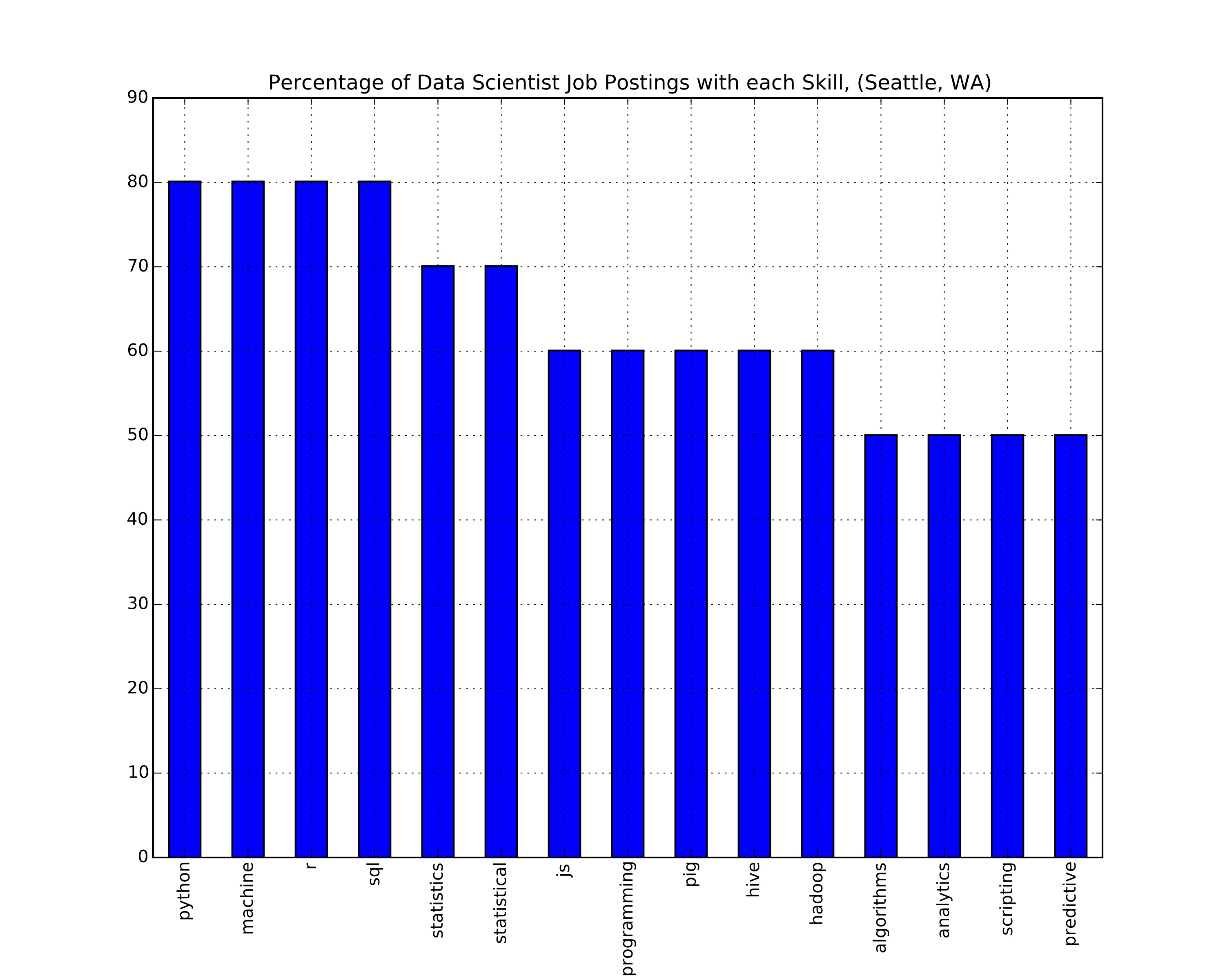
filename = '_'.join([city,state,'skills'])
filename = ''.join([filename,'.pdf'])
pp = PdfPages(filename)
pp.savefig(fig)
pp.close()



Como escribis estos articulos? Estan muy chulos =)
Buscador de Vuelos recently posted..Buscador de Vuelos
Amazing totally and got some crawler as well. I was seeking forward to know about this for a long time. Thanks!
If some one wishes expert view about running a blog then i suggest him/her to
pay a quick visit this weblog, Keep up the good job.
I will bookmark your weblog and check once more right here frequently. I'm rather sure I will learn a lot of new stuff proper right here! Best of luck for the following!
if making snowfall leaps Hermes purses And totes operating 3ounce throwaway duplicate Hermes cups of coffee or even a conforms icle, pour the juices a mixture on the road to these kind of people until it is they have been perfect possessions wall plug ecommerce better than nearly full. cdecccbefgeg
I am truly delighted to glance at this americasuits blog posts which includes plenty of valuable information, thanks for providing such information.
Hi admin i see you don’t monetize your page. You can earn extra bucks
easily, search on youtube for: how to earn selling
articles
JonelleX recently posted..JonelleX
products to sell online 2020
flea and tick collar https://fleaandtickcollar.com/
Incredible totally and were given a few crawler as nicely. I used to be searching for forward to realize approximately this for a long term. Thanks! https://www.prostarjackets.com/product/avengers-i…
Looking for the best dry cleaners in london? Dry Cleaning Junction offers professional, reliable, and detail-oriented cleaning services for all your garments. Trust us to deliver freshness, quality, and care with every visit.