Recently, at my work I have been doing a lot of performance analysis (also known as Profiling Tools) for the…

The one stop shop for everything Technology and Computer Related
Recently, at my work I have been doing a lot of performance analysis (also known as Profiling Tools) for the…
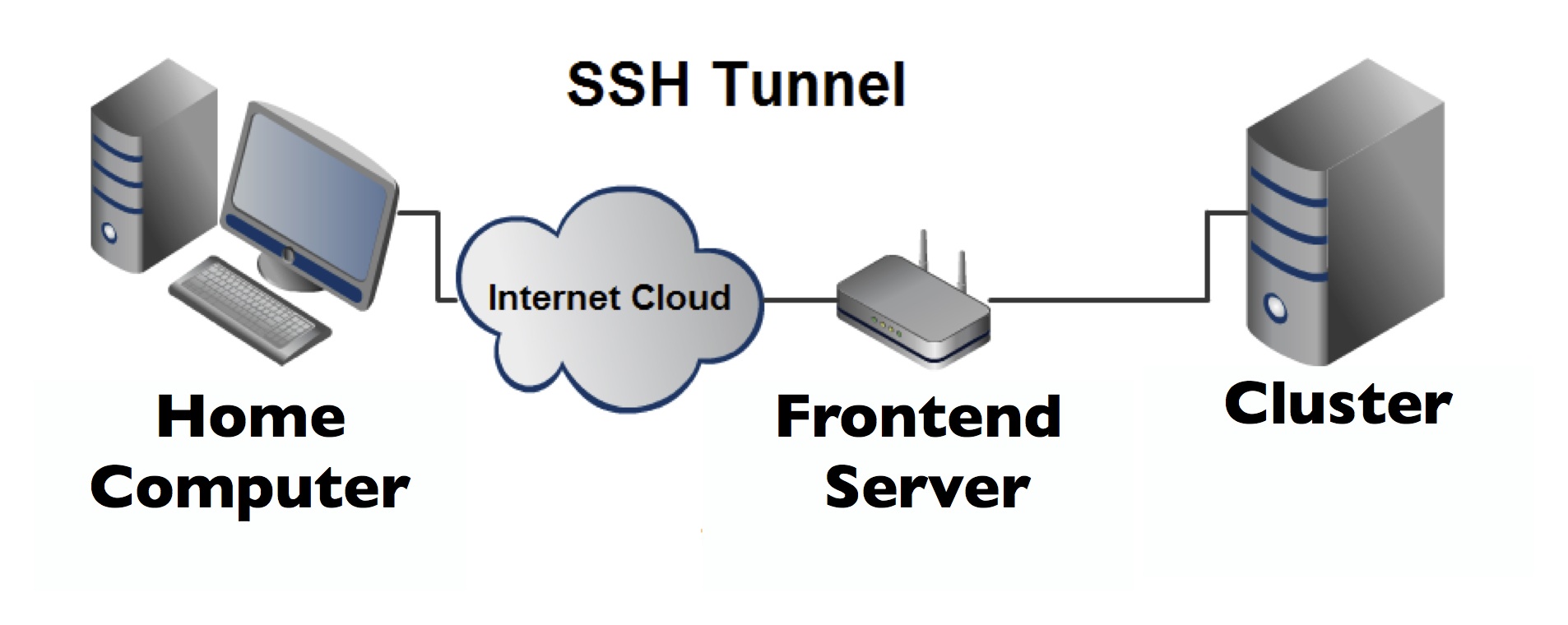
For those of you that read my blog often, you know that I admin the cluster that our research group…

There are times when I absolutely love being the admin for our group’s high performance computer. But there are also…
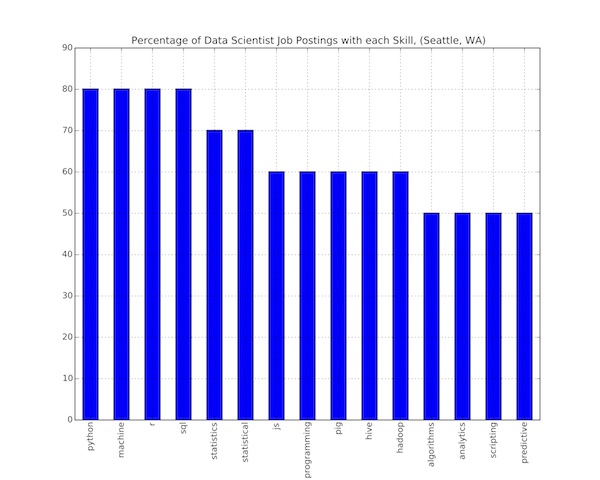
This is code that will pull each job posting for a specific job title in a specific location (or Nationally)…
We recently had an issue where we had to rebuild our RAID-6 array. After rebuilding the array, our cluster did…